
Facial landmark detection is a computer vision task in which a model needs to predict key points representing regions or landmarks on a human’s face – eyes, nose, lips, and others. Facial landmark detection is a base task which can be used to perform other computer vision tasks, including head pose estimation, identifying gaze direction, detecting facial gestures, and swapping faces.
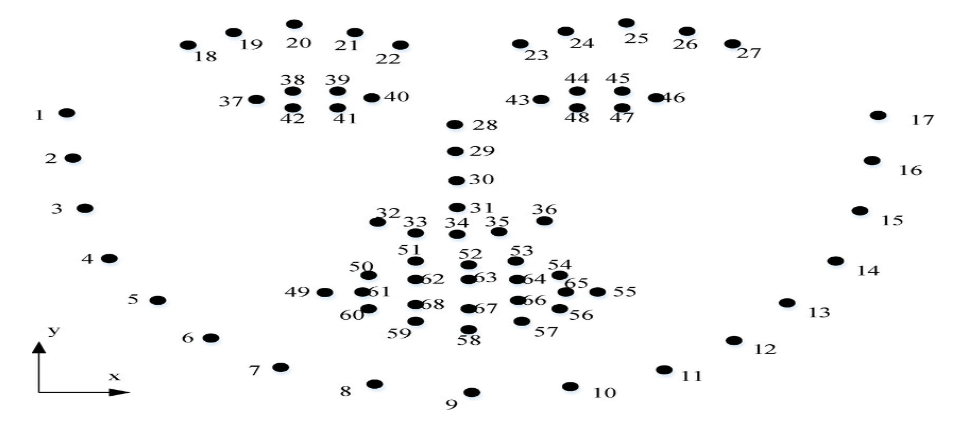
Many different face landmarks are used by various facial recognition technologies. For instance, the OpenFace library uses 68-landmarks and 2 landmark models, while the Dlib library employs 68 landmarks. The FaceNet model uses 128 landmarks compared to the MTCNN algorithm’s 5 landmarks.
Depending on the individual use case, several landmarks are used in facial recognition technology. For face alignment and posture estimation, for instance, the 68-landmark model from Dlib is helpful. The two-landmark model is helpful for estimating gaze. The 5-landmark of the MTCNN method is beneficial for face alignment and face detection. The 128-landmarks of the FaceNet model is helpful for facial identification.
In conclusion, based on their unique use cases, many facial recognition methods employ varying quantities of facial landmarks. From 2 to 128 landmarks may be used, depending on the situation. Each landmark has a unique purpose and value for completing distinct computer vision tasks.
Dlib
As a popular open-source machine learning, computer vision, and deep learning library Dlib offers the shape_predictor() function, which can be used to find facial landmarks in an image. The location and representation of prominent facial features like the eyes, brows, nose, mouth, and jawline are made possible by the use of facial landmarks. Face alignment, head pose estimation, face swapping, blink detection, and many other tasks have all been accomplished with success using them.
There are two steps involved in identifying facial landmarks in an image. Localizing the face in the image is the first step. A variety of methods, including deep learning-based algorithms and the built-in Haar cascades in OpenCV, can be used to achieve this. After obtaining the face ROI, we can use the shape predictor to identify important facial structures.
Numerous computer vision applications, including face recognition, emotion detection, and gaze tracking, have made use of facial landmarks. Other libraries, like OpenCV and MediaPipe, in addition to dlib, offer facial landmark detection capabilities.
OpenFace
The cutting-edge tool OpenFace is used for eye-gaze estimation, head pose estimation, facial action unit recognition, and facial landmark detection. It is an open-source toolkit that operates in real-time and can be used with only a basic webcam and no specialized hardware. The core computer vision algorithms of OpenFace produce cutting-edge results in each of the aforementioned tasks.
Tadas Baltruaitis and the Prof. Louis-Philippe Morency-led CMU MultiComp Lab initially worked together to develop OpenFace. While working at Rainbow Group, Cambridge University, some of the original algorithms were developed. The CMU MultiComp Lab is still actively working with Tadas Baltraitis to develop the OpenFace library.
MTCNN
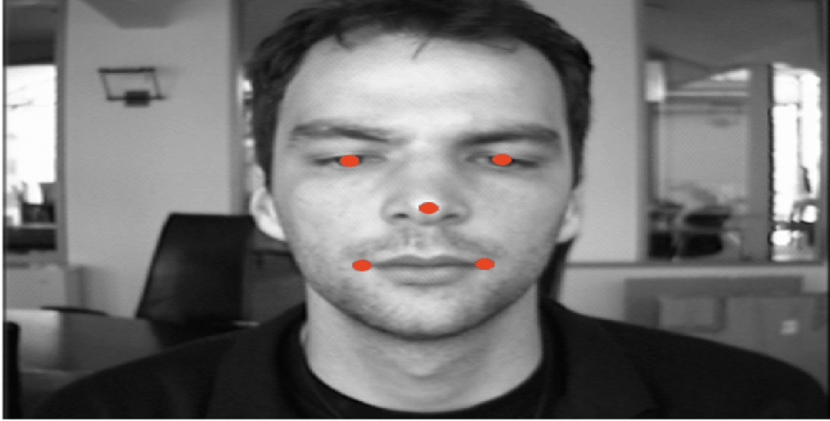
Multi-task Cascaded Convolutional Networks is the abbreviation for them. It is a deep learning-based face detection and alignment technique that locates faces in digital images or videos by using a cascading series of convolutional neural networks (CNNs). Convolutional networks are used in three stages of the process to identify faces and facial landmarks like the eyes, nose, and mouth. The paper suggests MTCNN as a method for combining both tasks (alignment and recognition) using multi-task learning. It uses a shallow CNN in the first stage to generate candidate windows quickly. Through a more intricate CNN, it improves the suggested candidate windows in the second stage. To further refine the outcome and output facial landmark positions, a third CNN that is more complex than the others is used in the third stage.
One of the most widely used and reliable face detection tools available today is MTCNN. It has been applied to a number of different tasks, including face recognition, emotion recognition, and video surveillance.
FaceNet

Google researchers presented FaceNet, a facial recognition system, in 2015. It is a deep learning architecture with an underpinning ZF-Net or Inception Network. FaceNet uses deep learning architectures to create a high-quality face mapping from the images and trains this architecture using a technique known as triplet loss. This loss function aims to reduce the squared distance between two image embeddings of the same identity (regardless of the image condition and pose), while increasing the squared distance between two images of different identities. Stochastic Gradient Descent (SGD) with backpropagation and AdaGrad are used to train the model. FaceNet produced cutting-edge results in numerous benchmark face recognition datasets, including Youtube Face Database and Labeled Faces in the Wild (LFW).